

Analyse univariée
Présentation des deux bases de données HDV2003 et RP2012
HDV2003
Ce fichier (HDV2003) est issu de l'enquête Histoire de vie qui porte sur la construction des identités et a pour objectifs de décrire, de hiérarchiser, d'analyser les différents types de liens sociaux qui permettent aux individus de s'intégrer dans la société française du début du XXIème siècle. Le fichier original contient 808 variables et 8403 observations. Télécharger le dictionnaire des données. Cependant, la base complète n'est pas disponible dans le package questionr, seulement quelques observations (2000) et quelques variables (20).
data("hdv2003")
head(hdv2003)RP2012
Échantillon du recensement national français de 2012. Il contient des résultats pour chaque ville française de plus de 2000 habitants, et un petit sous-ensemble de variables, à la fois en nombre et en proportion de population. Une base de données avec 5170 lignes et 60 variables.
data("rp2012")
head(rp2012)Analyse d'une variable quantitative
On parle de variable quantitative quand on a une variable de type numérique (un nombre) qui peut prendre un grand nombre de valeurs.
Maximum et minimum
Pour analyser une variable quantitative, on peut d'abord voir comment la série est repartie quelle est la valeur minimale (fonction min), la valeur maximale (fonction max).
Exécutez ce code suivant pour calculer le minimum et le maximum de la variable age de la base de données hdv2003
data(hdv2003)
##Maximum
max(hdv2003$age)
##Minimum
min(hdv2003$age)Moyenne et médiane
On peut calculer aussi les indicateurs de centralité, c'est-à-dire autour de quelle valeur se répartissent les données. Ainsi, on peut calculer la moyenne (fonction mean), la médiane (fonction median).
Exécutez ce code suivant pour calculer la moyenne et la médiane de la variable age de la base de données hdv2003
data(hdv2003)
##Moyenne
mean(hdv2003$age)
##Médiane
median(hdv2003$age)Variance, Ecart-type et Etendue
Les indicateurs de dispersion sont aussi souvent utilisés pour caractériser une variable quantitative. On peut calculer l'écart-type (fonction sd) de la variable, la variance (fonction var) ou l'étendue (max -- min) pour voir si les données sont regroupées ou au contraire dispersées.
Exécutez ce code pour calculer l'écart-type, la variance et l'étendue de la variable age de la base de donnée hdv2003.
data(hdv2003)
##Variance
var(hdv2003$age)
##Ecart-type
sd(hdv2003$age)
##Etendue
max(hdv2003$age)-min(hdv2003$age)Quartiles
Les quartiles (fonction quantile) aussi sont généralement utilisés pour mesurer la dispersion d'une série.
Le premier quartile est la valeur pour laquelle on a 25% des observations en dessous et 75% au-dessus;
Le deuxième quartile est la valeur pour laquelle on a 50% des observations en dessous et 50% au-dessus (c'est donc la médiane);
Le troisième quartile est la valeur pour laquelle on a 75% des observations en dessous et 25% au-dessus.
Exécutez ce code pour calculer le quartile d'ordre 25% et 75% de la variable age de la base de données hdv2003
data(hdv2003)
##Quartiles d'ordre 25%
quantile(hdv2003$age, prob=0.25)
##Quartile d'ordre 75%
quantile(hdv2003$age, prob=0.75)La fonction summary
La fonction summary permet d'avoir plusieurs indicateurs (min, max, quartiles et moyenne) en même temps.
Exécutez ce code pour calculer la moyenne, le minimum, le maximum et les quartiles de la variable age de la base de données hdv2003
data(hdv2003)
## Min, 1er quartile, Mediane, Moyenne, 3e quartile et maximum
summary(hdv2003$age)Représentation graphique d'une variable quantitative
Pour étudier aussi la distribution d'une variable quantitative, on peut faire une représentation graphique :
Un histogramme (hist)
Une boite à moustache (boxplot)
La fonction hista plusieurs arguments qui permettent de personnaliser le graphique :
Breaks : le nombre de classes,
Main : le titre du graphique
xlab : axe des abscisses
ylab : axe des ordonnées
col : couleur.
Ce document http://www.stat.columbia.edu/~tzheng/files/Rcolor.pdf donne beaucoup d'informations sur les couleurs intégrées dans R.
Construisons l'histogramme de la variable nombre d'heures passés devant la télé par jour.
data(hdv2003)
hist(hdv2003$heures.tv, main = "Nombre d'heures passées devant la télé par jour", xlab = "Heures", ylab = "Effectif", col="blue",breaks=10)La fonction boxplot est utilisée pour représenter la boite à moustache. Elle est souvent utilisée pour voir la dispersion des données (valeurs aberrantes). Elle est aussi utilisée pour comparer les distributions de plusieurs variables ou d'une même variable entre différents groupes.
data(hdv2003)
##BOITE A MOUSTACHE
boxplot(hdv2003$heures.tv, main = "Nombre d'heures passées devant la télé par jour", ylab = "Heures")Pour une interprétation plus détaillée de la boite à moustache, veuillez consulter ce document http://pbil.univ-lyon1.fr/R/pdf/lang04.pdf
Vidéo récapitulative
Tester vos connaissances
Exercices
- On souhaite étudier la répartition du temps passé devant la télévision par les enquêtés (variable heures.tv de la base hdv2003). Pour cela, affichez les principaux indicateurs de cette variable : valeur minimale, maximale, étendue, moyenne, médiane et écart-type. Représentez ensuite sa distribution par un histogramme en 10 classes.
Le code pour importer hdv2003 est déjà présent. Nous avons aussi retiré les lignes où heures.tv est absent (NA).
data("hdv2003")
hdv2003 <- hdv2003 %>% filter(!is.na(heures.tv))Analyse d'une variable qualitative
Une variable qualitative est une variable qui ne peut prendre qu'un nombre limité de valeurs, appelées modalités. Par exemple, la variable sexe avec deux modalités: 1. Masculin, 2. Féminin est une variable qualitative.
Le mode est la modalité qui a le plus grand effectif.
Pour étudier une variable qualitative, on fait généralement un tri à plat (fonction table) c'est-à-dire la répartition de la variable suivant ses modalités.
Faisons le tri à plat de la variable qualif (qualification) dans la base de données hdv2003
data("hdv2003")
## Tri à plat de la variable qualif
table(hdv2003$qualif)##
## Ouvrier specialise Ouvrier qualifie Technicien
## 203 292 86
## Profession intermediaire Cadre Employe
## 160 260 594
## Autre
## 58On a 6 modalités et le mode est la modalité Employé, il a la plus grande valeur (594).
On peut stocker le résultat de table dans un objet et utiliser l'objet dans la suite si on veut ordonner par exemple les données. Faisons le tri à plat de la variable qualification et ordonnez ensuite les valeurs.
data("hdv2003")
## Tri à plat de la variable qualif
table(hdv2003$qualif)##
## Ouvrier specialise Ouvrier qualifie Technicien
## 203 292 86
## Profession intermediaire Cadre Employe
## 160 260 594
## Autre
## 58tabQualif<-table(hdv2003$qualif)
sort(tabQualif)##
## Autre Technicien Profession intermediaire
## 58 86 160
## Ouvrier specialise Cadre Ouvrier qualifie
## 203 260 292
## Employe
## 594Il faut noter que par défaut la fonction table n'affiche pas les valeurs manquantes. Pour les afficher, il faut utiliser l'argument useNA = "always".
Par exemple:
table (hdv2003$sexe, useNA= "always")##
## Homme Femme <NA>
## 899 1101 0La fonction table ne donne que les effectifs et parfois il est plus pertinent de travailler avec les proportions. On peut utiliser la fonction prop.table pour calculer ces proportions.
prop.table(table(hdv2003$qualif))*100##
## Ouvrier specialise Ouvrier qualifie Technicien
## 12.280702 17.664852 5.202662
## Profession intermediaire Cadre Employe
## 9.679371 15.728978 35.934664
## Autre
## 3.508772On peut utiliser la fonction round pour diminuer le nombre de chiffres après la virgule comme suit:
round(prop.table(table(hdv2003$qualif))*100, 2)##
## Ouvrier specialise Ouvrier qualifie Technicien
## 12.28 17.66 5.20
## Profession intermediaire Cadre Employe
## 9.68 15.73 35.93
## Autre
## 3.51Il existe une fonction freq du package questionr qui permet de faire du tri à plat
freq(hdv2003$nivetud)La colonne n représente les effectifs, la colonne % représente les pourcentages, la colonne %val représente les pourcentages des valeurs valides calculées sans les données manquantes. Freq a plusieurs arguments pour personnaliser son affichage. On peut ajouter l'argument total qui permet d'afficher les totaux, on peut ajouter sort qui permet d'ordonner, on peut ajouter valid qui permet d'afficher ou pas les pourcentages de valeurs valides. Les autres arguments sont détaillés dans l'annexe.
##TRI A PLAT AVEC LES PROPORTIONS
freq(hdv2003$nivetud, valid= FALSE, total = TRUE, sort = "dec")Comme dans le cas des variables quantitatives, on peut utiliser aussi la fonction summary pour faire le tri à plat. Dans ce cas, on aura les effectifs et une colonne NA'S qui représente les données manquantes.
summary(hdv2003$qualif)## Ouvrier specialise Ouvrier qualifie Technicien
## 203 292 86
## Profession intermediaire Cadre Employe
## 160 260 594
## Autre NA's
## 58 347Vidéo récapitulative
Représentations graphiques
Pour représenter une variable qualitative, on peut recourir à différents types de graphiques tels que le diagramme en bâton (barplot), le diagramme en barre (plot) le diagramme de Cleveland (dotchart), le diagramme circulaire (pie). Ces fonctions ne s'appliquent pas directement sur la variable, mais au tri à plat obtenu avec la fonction table. On peut aussi utiliser la fonctionsort pour ordonner les valeurs pour une meilleure présentation des graphiques.
##DIAGRAMME CIRCULAIRE
pie(table(hdv2003$sexe))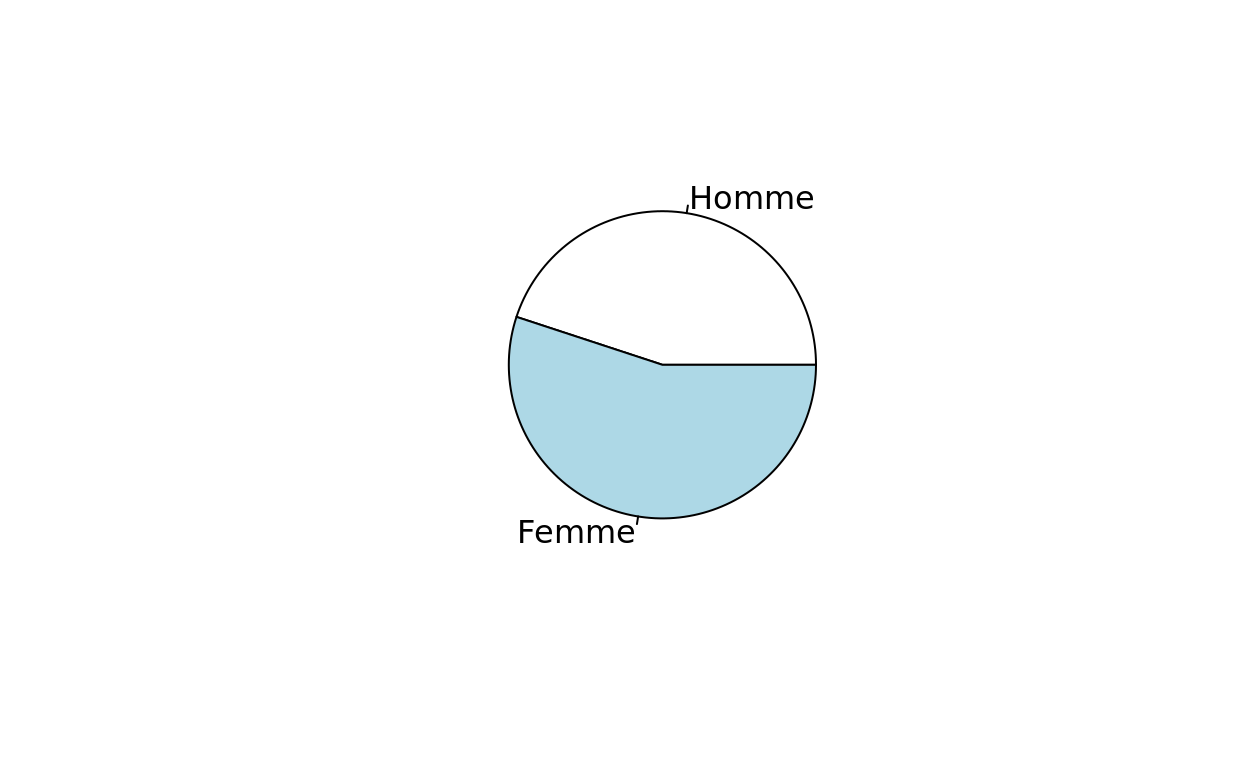
##DIAGRAMME EN BARRE AVEC VARIABLE "IMPORTANCE DU TRAVAIL" ORDONNEE
barplot(sort(table(hdv2003$trav.imp)))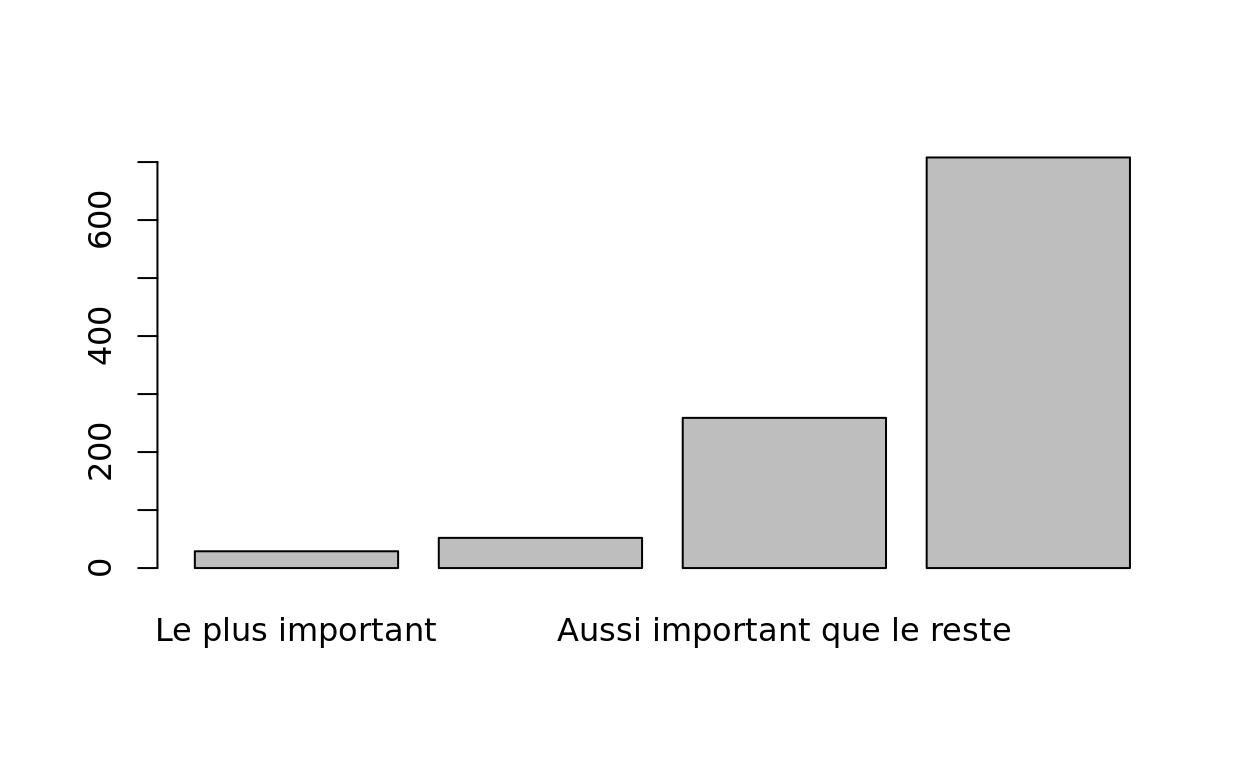
##DIAGRAMME EN BATON AVEC VARIABLE "IMPORTANCE DU TRAVAIL" ORDONNEE
plot(sort(table(hdv2003$trav.imp)))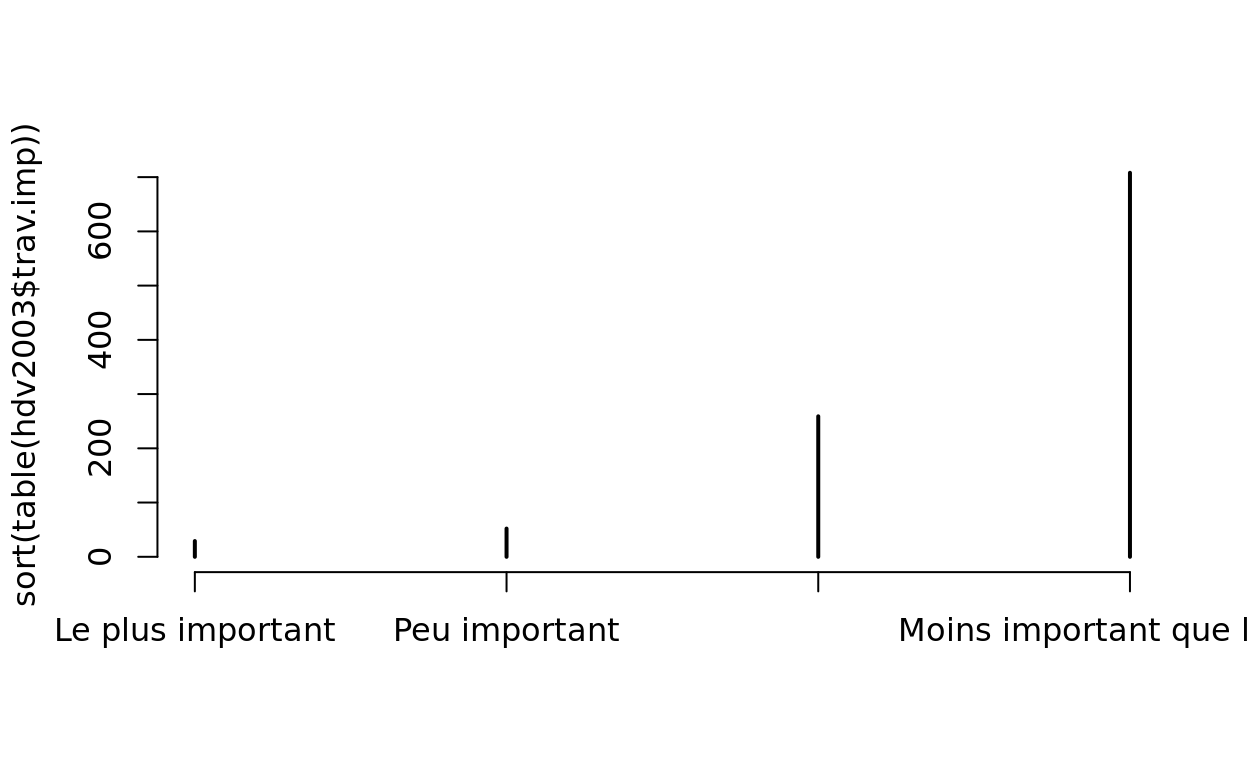
##DIAGRAMME DE CLEVELAND AVEC VARIABLE "IMPORTANCE DU TRAVAIL" ORDONNEE
dotchart(sort(as.matrix(table(hdv2003$trav.imp))[, 1]),pch = 19)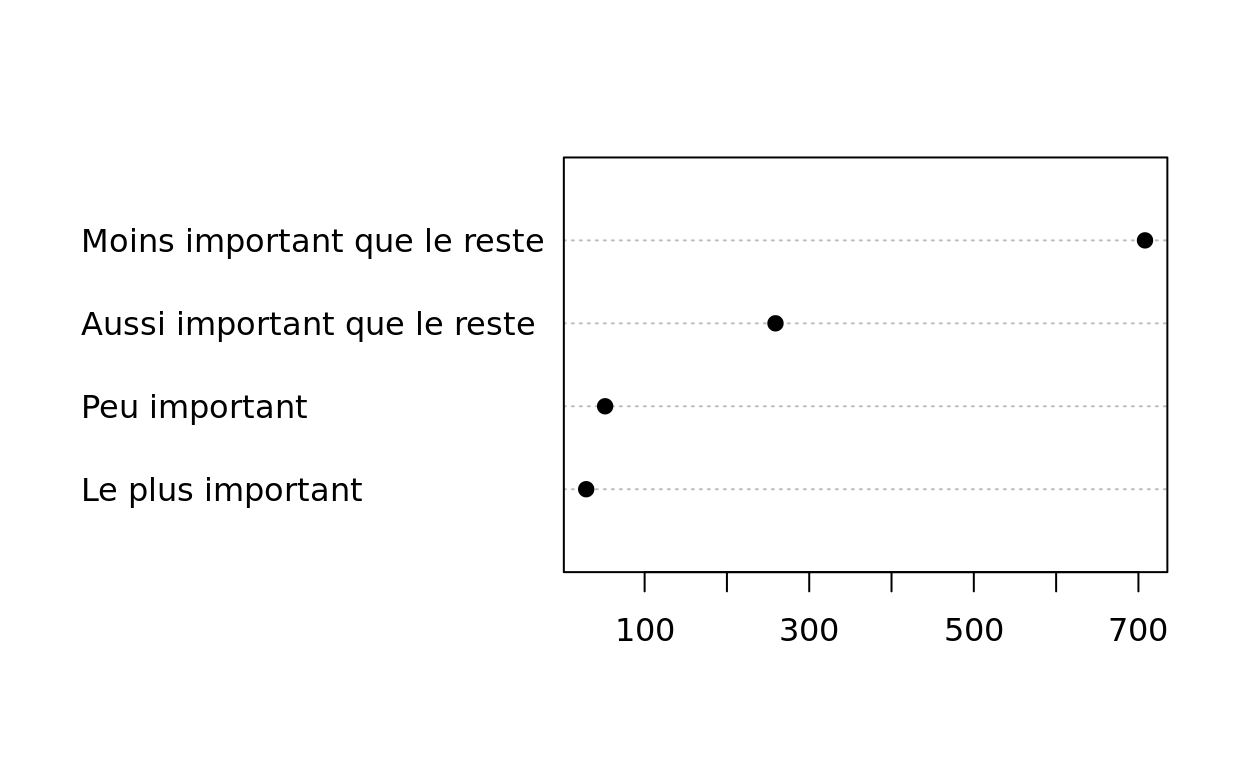
Il faut transformer le tri à plat en matrice pour respecter le fonctionnement de la fonction, d'où l'utilisation de as.matrix. On aura le même résultat si on ne l'utilise pas, mais avec un message d'avertissement (warning). L'argument pch permet de spécifier le symbole à utiliser. Il peut prendre soit un nombre entier compris entre 0 et 25, soit un caractère textuel (voir ci-dessous).

Exercice
On s'intéresse à l'importance accordée par les enquêtés à leur travail (variable
trav.impde la base de donnéeshdv2003). Faites un tri à plat des effectifs des modalités de cette variable avec la commandetable. Faites un tri à plat affichant le nombre de chaque modalité. Enlevez les valeurs manquantes grâce à l'argumentuseNA(lisez la documentation pour savoir comment l'utiliser).Représentez graphiquement les effectifs des modalités à l'aide d'un graphique en barres.
Utilisez l'argument col de la fonctionbarplotpour modifier la couleur du graphique en tomato.
Utilisez ce code pour importer la base: data("hdv2003")
data("hdv2003")
barplot(sort(table(hdv2003$trav.imp), useNA="no"), col="tomato")Analyse bivariée
L'analyse bivariée consiste à étudier deux variables en même temps afin de déterminer la relation empirique entre elles.
Croisement de deux variables qualitatives
Pour étudier deux variables qualitatives, on fait généralement un tableau croisé. On peut utiliser la fonction table pour faire le tableau.
##Tableau croisé de la variable importance du travail en fonction du sexe
table(hdv2003$trav.imp, hdv2003$sexe)##
## Homme Femme
## Le plus important 13 16
## Aussi important que le reste 159 100
## Moins important que le reste 328 380
## Peu important 20 32En ligne, on a la variable importance du travail et en colonne le sexe. Donc on peut dire que 159 hommes ont dit que le travail est moins important que le reste. La meilleure interprétation est de passer par les pourcentages colonnes ou ligne. Pour ce faire, on utilise les fonctions lprop et cprop du package questionr.
tab <-table(hdv2003$trav.imp, hdv2003$sexe)
lprop(tab)##
## Homme Femme Total
## Le plus important 44.8 55.2 100.0
## Aussi important que le reste 61.4 38.6 100.0
## Moins important que le reste 46.3 53.7 100.0
## Peu important 38.5 61.5 100.0
## All 49.6 50.4 100.0lprop permet de calculer les pourcentages lignes. Ainsi, on peut dire que parmi ceux qui ont répondu que le travail est plus important, il y a 44,8% d'hommes et 55,2% de femmes.
tab <-table(hdv2003$trav.imp, hdv2003$sexe)
cprop(tab)##
## Homme Femme All
## Le plus important 2.5 3.0 2.8
## Aussi important que le reste 30.6 18.9 24.7
## Moins important que le reste 63.1 72.0 67.6
## Peu important 3.8 6.1 5.0
## Total 100.0 100.0 100.0cprop permet de calculer les pourcentages colonnes. Ainsi, on peut dire que parmi les hommes, il y a 63,1% qui ont répondu que le travail est moins important que le reste.
Les pourcentages totaux s'obtiennent avec la fonction prop.
tab <-table(hdv2003$trav.imp, hdv2003$sexe)
prop(tab)##
## Homme Femme Total
## Le plus important 1.2 1.5 2.8
## Aussi important que le reste 15.2 9.5 24.7
## Moins important que le reste 31.3 36.3 67.6
## Peu important 1.9 3.1 5.0
## Total 49.6 50.4 100.0On peut utiliser une autre fonction qui fait un peu le même travail que table. Il s'agit de la fonction xtabs. On utilisera le symbole ~ pour indiquer la variable qu'il faut utiliser. S'il y a plusieurs variables, on les sépare par le symbole +.
xtabs(~sexe, hdv2003)## sexe
## Homme Femme
## 899 1101xtabs(~trav.imp+sexe, hdv2003)## sexe
## trav.imp Homme Femme
## Le plus important 13 16
## Aussi important que le reste 159 100
## Moins important que le reste 328 380
## Peu important 20 32Pour calculer les pourcentages ligne, colonnes et totaux, on peut faire la même chose que table en utilisant les fonctions cprop, lprop et prop de la même manière.
Avec xtabs, on peut faire un tableau de plus de deux variables.
xtabs(~trav.imp+sexe+sport, hdv2003)## , , sport = Non
##
## sexe
## trav.imp Homme Femme
## Le plus important 9 11
## Aussi important que le reste 87 58
## Moins important que le reste 165 223
## Peu important 9 24
##
## , , sport = Oui
##
## sexe
## trav.imp Homme Femme
## Le plus important 4 5
## Aussi important que le reste 72 42
## Moins important que le reste 163 157
## Peu important 11 8Représentation graphique
Pour représenter deux variables qualitatives, on peut utiliser un diagramme en mosaïque avec la fonction mosaicplot.
Exécutez le code suivant du diagramme en mosaïque
data(hdv2003)
mosaicplot(qualif ~ sexe, data = hdv2003, shade = TRUE, main = "Graphe en mosaïque")La fonction mosaicplot comporte plusieurs arguments parmi lesquels l'argument shade qui nous permet de produire des tracés en mosaïque étendue (si FALSE), ou un vecteur numérique d'au plus 5 nombres positifs distincts donnant les valeurs absolues des points de coupure pour les résidus (si TRUE).
Interprétation du graphique
Chaque rectangle correspond à une case du tableau où la largeur correspond au pourcentage des modalités en colonnes (il y a beaucoup plus d'employés que de technicien) et la hauteur correspond aux proportions des colonnes (la proportion d'hommes chez les ouvriers qualifiés est supérieure à celle des cadres). La couleur de la case correspond au résidu du test de khi-deux correspondant.
Pour avoir plus d'informations sur les fonctions (arguments, valeurs retournées), vous pouvez utiliser la fonction help. Exécutez ce code ci-dessous pour plus d'informations sur la fonction mosaicplot.
help(mosaicplot)Vidéo Récapitulative
Croisement d'une variable quantitative et d'une variable qualitative
Le croisement d'une variable quantitative et d'une variable qualitative permet de voir comment la variable quantitative est repartie suivant les modalités de la variable qualitative. La boite à moustache (fonction boxplot) est généralement utilisée pour voir cette dispersion. Par exemple on peut visualiser la répartition des âges selon la fréquentation ou non du cinéma.
Exécutez le code suivant pour générer la boite à moustache
data(hdv2003)
##CROISEMENT D'UNE VARIABLE QUALITATIVE ET D'UNE VARIABLE QUANTITATIVE
boxplot(hdv2003$age ~ hdv2003$cinema)L'interprétation d'un boxplot est la suivante : Les bords inférieurs et supérieurs du carré central représentent le premier et le troisième quartile de la variable représentée sur l'axe vertical. On a donc 50% de nos observations dans cet intervalle. Le trait horizontal dans le carré représente la médiane. Enfin, des "moustaches" s'étendent de chaque côté du carré, jusqu'aux valeurs minimales et maximales, avec une exception : si des valeurs sont éloignées du carré de plus de 1,5 fois l'écart interquartile (la hauteur du carré), alors on les représente sous forme de points (symbolisant des valeurs considérées comme "extrêmes").
On remarque que ceux qui fréquentent le cinéma sont sensiblement plus jeunes que ceux qui ne le fréquentent pas.
Vidéo Récapitulative
Croisement de deux variables quantitatives
L'étude de deux variables quantitatives se fait d'abord par une représentation graphique de type nuage de points pour voir le comportement de deux variables (tendance de corrélation ou pas). On peut utiliser la base de données rp2012 qui comporte beaucoup plus de variables quantitatives. On peut ainsi représenter le pourcentage de cadres selon le pourcentage de diplômés du supérieur.
Exécutez le code suivant:
data(rp2012) ##Accés de la base de données rp2012
##CROISEMENT DE DEUX VARIABLES QUANTITATIVES
plot(rp2012$cadres, rp2012$dipl_sup)D'après le graphique ci-dessus, on obtient une relation de dépendance claire entre le pourcentage des cadres et le pourcentage des diplômés du supérieur. On peut le tester numériquement en calculant le coefficient de corrélation qu'on verra dans la partie corrélation.
Corrélations et Test
- Test de Khi-Deux
Si on veut tester l'hypothèse d'indépendance des lignes et des colonnes d'un tableau croisé de variables qualitatives, on peut utiliser le test d'indépendance de khi-deux. La fonction chisq.test appliqué au tableau croisé permet d'effectuer ce test. Testons l'hypothèse d'indépendance des deux variables « faire du sport » et « sexe ».
data(hdv2003)
##Test de Khi-deux
tab<- table(hdv2003$sexe, hdv2003$sport)
chisq.test(tab)X-squared, la valeur de la statistique du Khi-deux pour notre tableau, c'est-à-dire une "distance" entre notre tableau observé et celui attendu si les deux variables étaient indépendantes.
df, le nombre de degrés de liberté du test.
p-value, indique la probabilité d'obtenir une valeur de la statistique du Khi-deux au moins aussi extrême sous l'hypothèse d'indépendance.
Ici, le p-value est extrêmement faible (4.6e-05), est inférieur au seuil de décision généralement choisi (5% ou 0.05). On peut donc rejeter l'hypothèse d'indépendance des lignes et des colonnes du tableau.
- Corrélation linéaire (Pearson)
L'association linéaire entre deux variables quantitatives est mesurée par le coefficient de corrélation linéaire. Sa valeur varie entre -1 et 1. On parle d'une association linéaire négative parfaite si la valeur vaut 1 et d'une association linéaire positive parfaite si la valeur vaut 1. La valeur 0 indique une non-association linéaire entre les deux variables. La fonction cor permet de calculer la corrélation. Ainsi, calculons la corrélation entre le pourcentage de cadres et celui de diplômés du supérieur :
data(rp2012)
##COEFFICIENT DE CORRELATION LINEAIRE
cor(rp2012$cadres, rp2012$dipl_sup)Le coefficient de corrélation est égal à 0,93, proche de 1. Donc, on peut dire que les deux variables sont corrélées positivement.
Calculons le coefficient de corrélation entre le pourcentage de propriétaire et le pourcentage de diplômés du supérieur :
data(rp2012)
cor(rp2012$proprio, rp2012$dipl_sup)Le coefficient de corrélation est très faible (0.05), donc on note une absence de liaison entre les deux variables.
Vidéo Récapitulative
Exercices (tirés du document "Introduction à R et au tidyverse" de Julien Barber)
Exercice 1:
Dans le jeu de données hdv2003, faire le tableau croisé entre la catégorie socio-professionnelle (variable qualif) et le fait de croire ou non en l'existence des classes sociales (variable clso). Identifier la variable indépendante et la variable dépendante, et calculer les pourcentages ligne ou colonne. Interpréter le résultat. Faire un test du Khi-deux. Peut-on rejeter l'hypothèse d'indépendance ?
Représenter ce tableau croisé sous la forme d'un mosaicplot en colorant les cases selon les résidus du test de Khi-deux.
data(hdv2003)
tab <- table(hdv2003$qualif, hdv2003$clso)
chisq.test(tab)
#On peut rejeter l'hypothèse car la valeur de p est inférieur à 0.05Exercice 2:
Toujours sur le jeu de données hdv2003, faire le boxplot qui croise le nombre d'heures passées devant la télévision (variable heures.tv) avec le statut d'occupation (variable occup). Calculer la durée moyenne devant la télévision en fonction du statut d'occupation à l'aide de tapply.
data(hdv2003)
boxplot(hdv2003$heures.tv ~ hdv2003$occup, las=2)#las=2 met le nom des occupations à la verticalExercice 3:
Sur le jeu de données rp2012, représenter le nuage de points croisant le pourcentage de personnes sans diplôme (variable dipl_aucun) et le pourcentage de propriétaires (variable proprio).
Calculer le coefficient de corrélation linéaire correspondant.
data(rp2012)
plot(rp2012$dipl_aucun, rp2012$proprio)
cor(rp2012$dipl_aucun,rp2012$proprio)Régression linéaire
Quand on a une corrélation forte entre deux variables quantitatives, on peut penser à faire une régression linéaire, c'est-à-dire exprimer l'une en fonction de l'autre variable.
La fonction lm est utilisée pour faire une régression linéaire simple.
La proportion de cadres et la proportion des diplômés du supérieur sont fortement corrélées. Faisons la régression entre ces deux variables.
data(rp2012)
##REGRESSION LINEAIRE
lm(rp2012$cadres ~ rp2012$dipl_sup)Le symbole Tilde ~ est utilisé pour séparer la variable d'intérêt et la variable explicative. Si on a plusieurs variables explicatives, on les sépare par le signe +.
L'Intercept représente la constante du modèle, c'est-à-dire ici l'ordonnée à l'origine qui vaut 0.92.
Le coefficient associé à la variable explicative (dipl_sup) vaut 1.08.
Pour avoir des résultats plus détaillés, on peut stocker le résultat de la régression dans un objet et utiliser la fonction summary.
data(rp2012)
reg <- lm(rp2012$cadres ~ rp2012$dipl_sup)
summary(reg)Call : la formule du modèle ;
Residuals : des statistiques descriptives des résidus ;
Coefficients : un tableau à deux entrées où les lignes correspondent aux coefficients associés aux variables explicatives, et les colonnes, dans l'ordre, à l'estimation du coefficient, l'écart-type estimé, la valeur du test de Student de nullité statistique du coefficient et enfin la p-value associée à ce test, suivie d'un symbole pour lire rapidement la significativité ;
Signif. codes : les significations des symboles de niveau de significativité ;
Residual standard error : estimation de l'écart-type de l'aléa et degré de liberté ;
Multiple R-squared : coefficient de détermination ;
Adjusted R-squared : coefficient de détermination ajusté ;
F-statistic : valeur de la statistique de Fisher du test de significativité globale, ainsi que les degrés de liberté et la p-value associée au test.
La variable dipl_sup est significative, le coefficient est significativement différent de 0. On remarque que la part des diplômés du supérieur augmente avec la part des cadres. On peut représenter la droite de régression avec la fonction abline.
data(rp2012)
reg <- lm(rp2012$cadres ~ rp2012$dipl_sup)
plot(rp2012$dipl_sup, rp2012$cadres)
abline(reg, col="blue")La fonction reg retourne plusieurs éléments qu'on peut accéder en utilisant le reg suivi du symbole $.
D'abord, sortons tous les éléments retournés par reg. Pour ce faire, on utilise la fonction names.
data(rp2012)
reg <- lm(rp2012$cadres ~ rp2012$dipl_sup)
names(reg)Les éléments les plus utilisés sont :
Coefficients : un vecteur de coefficients ;
residuals : les résidus ;
fitted.values : les valeurs estimées ;
df.residual : nombre de degrés de liberté.
Ainsi, pour accéder aux coefficients, on utilise la commande suivante :
data(rp2012)
reg <- lm(rp2012$cadres ~ rp2012$dipl_sup)
reg$coefficientsVidéo Récapitulative
Exercice:
Nous donnons les couples d'observations suivants :
| Xi | 18 | 7 | 14 | 31 | 21 | 5 | 11 | 16 | 26 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Yi | 55 | 17 | 36 | 85 | 62 | 18 | 33 | 41 | 63 | 87 |
La première étape est d'obtenir les données. Enregistez-les dans un format adapté.
Tracez le nuage de points des couples (xi, yi). À la vue de ce diagramme, pouvons-nous soupçonner une liaison linéaire entre ces deux variables ?
Déterminez pour ces observations la droite des moindres carrés, c'est-à-dire donner les coefficients de la droite des MC.
Tracez ensuite la droite sur le même graphique.
Xi <- c(18, 7, 14, 31, 21, 5, 11, 16, 26, 9)
Yi <- c(55, 17, 36, 85, 62, 18, 33, 41, 63, 87)
plot(Xi, Yi)
reg <- lm(Yi ~ Xi)
reg$coefficients
abline(reg, col="blue")Régression logistique
La régression logistique, également appelée modèle logit, est utilisée pour modéliser des variables de résultat dichotomiques.
Soit Y la variable à prédire (variable expliquée) et X = (X1, X2, ......, Xj) les variables prédictives (variables explicatives) .
Dans le cadre de la régression logistique binaire, la variable Y prend deux modalités possibles {1, 0} . Les variables Xj sont exclusivement continues ou binaires.
La régression logistique est largement répandue dans de nombreux domaines. On peut citer de façon non exhaustive :
En médecine, elle permet par exemple de trouver les facteurs qui caractérisent un groupe de sujets malades par rapport à des sujets sains.
Dans le domaine des assurances, elle permet de cibler une fraction de la clientèle qui sera sensible à une police d'assurance sur tel ou tel risque particulier.
Dans le domaine bancaire, pour détecter les groupes à risque lors de la souscription d'un crédit.
En économétrie, pour expliquer une variable discrète. Par exemple, les intentions de vote aux élections.
Exemple 1 . Supposons que nous nous intéressons aux facteurs qui influencent la victoire d'un candidat politique aux élections. La variable de résultat (réponse) est binaire (0/1); Gagner ou perdre. Les variables prédictives d'intérêt sont le montant d'argent dépensé pour la campagne, le temps passé à faire campagne et si le candidat est ou non un titulaire.
Exemple 2 . Un chercheur s'intéresse à la façon dont les variables, telles que le GRE (scores aux examens d'études supérieures), la moyenne cumulative (moyenne pondérée cumulative) et le prestige de l'établissement de premier cycle, affectent l'admission aux études supérieures. La variable de réponse, admettre/ne pas admettre, est une variable binaire.
Pour la pratique l'exemple 2 sera fait. D'abord, importons les données et présentons-les.
mydata <- read.csv("https://stats.idre.ucla.edu/stat/data/binary.csv")
## Afficher les premieres observations
head(mydata)La base de données contient 4 variables:
admit: variable binaire dont 1 représente admis à l'université et 0 non admis à l'université;
gre: Scores aux examens d'études supérieures;
gpa: La moyenne cumulative des notes;
rank: Le prestige de l'établissement de premier cycle.
La variable rank prend les valeurs 1 à 4. Les institutions ayant un rank de 1 ont le plus grand prestige, tandis que celles ayant un rang de 4 ont le plus faible.
On peut faire une analyse descriptive rapide de la base en utilisant la fonction summary
summary(mydata)## admit gre gpa rank
## Min. :0.0000 Min. :220.0 Min. :2.260 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:520.0 1st Qu.:3.130 1st Qu.:2.000
## Median :0.0000 Median :580.0 Median :3.395 Median :2.000
## Mean :0.3175 Mean :587.7 Mean :3.390 Mean :2.485
## 3rd Qu.:1.0000 3rd Qu.:660.0 3rd Qu.:3.670 3rd Qu.:3.000
## Max. :1.0000 Max. :800.0 Max. :4.000 Max. :4.000sapply(mydata, sd)## admit gre gpa rank
## 0.4660867 115.5165364 0.3805668 0.9444602La moyenne des notes obtenues est égale à 3,39 avec un écart de 0,38. Alors que le score moyen aux examens d'études supérieures est égal à 587,7 avec un écart de 115,5. Les variables gre et gpa seront considérées comme des variable continues et la variable rank comme une variable qualitative.
Ainsi, on peut faire un tri à plat de la variable à expliquer (admit) et l'une des variables explicatives (rank).
tab<-table(mydata$rank, mydata$admit)
cprop(tab)##
## 0 1 All
## 1 10.3 26.0 15.2
## 2 35.5 42.5 37.8
## 3 34.1 22.0 30.2
## 4 20.1 9.4 16.8
## Total 100.0 100.0 100.0L'analyse suivant la réputation montre que 26% des élèves acceptées proviennent d'une prestigieuse école (réputation de niveau 1) contre 42,5% qui sont issus d'une école de niveau de réputation 2. Parmi les non acceptés, 10,3% sont sortis dans de prestigieuses écoles, 35,5% dans des écoles de niveau de réputation 2.
La fonction qui permet de faire la régression logistique dans R est glm du package stats en choisissant comme argument family="binomial". Le symbole ~ sépare la variable à expliquer (admit) et les variables explicatives et les variables explicatives sont séparées par le symbole +. La variable rank est transformée en facteur avant de la mettre dans le modèle. Exécutez le code suivant pour réaliser la régression logistique de la variable admit sur les variables gpa, gre et rank.
mydata <- read.csv("https://stats.idre.ucla.edu/stat/data/binary.csv")
mydata$rank <- factor(mydata$rank)
mylogit <- glm(admit ~ gre + gpa + rank, data = mydata, family = "binomial")
summary(mylogit)On utilise la fonction summary pour afficher les résultats détaillés de la régression logistique. Les variables ont significatives au moins au seuil de 5% (Pr(>|z|)<0,05). Les variables gre et gpa influencent positivement l'acceptation de l'élève à l'université. Par contre, le niveau de prestige 2 influence négativement l'acceptation de l'élève à l'université comparé au niveau de prestige 1, tout comme les niveaux de prestige 3 et 4.
On peut calculer les exponentielles des coefficients pour avoir les odds-ratios. On extrait d'abord les coefficients avec la fonction coef, ensuite on calcule l'exponentielle avec la fonction exp comme suit:
##
## Call:
## glm(formula = admit ~ gre + gpa + rank, family = "binomial",
## data = mydata)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.6268 -0.8662 -0.6388 1.1490 2.0790
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.989979 1.139951 -3.500 0.000465 ***
## gre 0.002264 0.001094 2.070 0.038465 *
## gpa 0.804038 0.331819 2.423 0.015388 *
## rank2 -0.675443 0.316490 -2.134 0.032829 *
## rank3 -1.340204 0.345306 -3.881 0.000104 ***
## rank4 -1.551464 0.417832 -3.713 0.000205 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 499.98 on 399 degrees of freedom
## Residual deviance: 458.52 on 394 degrees of freedom
## AIC: 470.52
##
## Number of Fisher Scoring iterations: 4exp(coef(mylogit))## (Intercept) gre gpa rank2 rank3 rank4
## 0.0185001 1.0022670 2.2345448 0.5089310 0.2617923 0.2119375On peut aussi calculer les intervalles de confiance avec la fonction confint et mettre tout dans un tableau avec la fonction cbind.
exp(cbind(OR = coef(mylogit), confint(mylogit)))## OR 2.5 % 97.5 %
## (Intercept) 0.0185001 0.001889165 0.1665354
## gre 1.0022670 1.000137602 1.0044457
## gpa 2.2345448 1.173858216 4.3238349
## rank2 0.5089310 0.272289674 0.9448343
## rank3 0.2617923 0.131641717 0.5115181
## rank4 0.2119375 0.090715546 0.4706961Avec le calcul des odds ratio, nous pouvons maintenant dire que pour une augmentation d'une unité de la moyenne des notes, les chances d'être admis dans une école d'études supérieures (par rapport à une non-admission) augmentent d'un facteur de 2,23. De même les chances d'être admis dans une école d'études supérieures (par rapport à une non-admission) sont 0,5 fois plus petites si on est issue d'un établissement de réputation 2 par rapport à un établissement de réputation 1. L'odds-ratio lié à la variable test est sensiblement égale à 1 alors l'effet est négligeable.
Vidéo Récapitulative
Exercice:
Utilisez la base de données mtcars qui contient des informations sur 32 véhicules. Parmi ces variables figurent:
am : Type de transmission (variable dichotomique et variable à expliquer)
hp : Puissance brute du véhicule
wt : Poids du véhicule (1000 lbs)
cyl : Nombre de cylindres
Faites un modèle de régression logistique avec comme variable à expliquer am et comme variables explicatives hp, wt et cyl Interprétez les résultats.
## Importation des données
library(dplyr)
data("mtcars")library(dplyr)
data("mtcars")
mylogit <- glm(am ~ hp + wt + cyl, data = mtcars, family = "binomial")
summary(mylogit)